

NVIDIA Blackwell Ultra Dominates MLPerf AI Training, GB300 NVL72 Breaks Record with 10-Minute Llama 405B Training
NVIDIA continues to assert its dominance in the AI training sector with the unveiling of their Blackwell Ultra-based GB300 NVL72 platform. This cutting-edge technology has secured victories across all MLPerf training benchmarks, delivering unprecedented AI training performance.
NVIDIA’s Stellar Performance in MLPerf AI Training Benchmarks
Renowned for leading AI performance, NVIDIA’s data center GPUs have once again proven their prowess with the Blackwell-based GB300 NVL72 platform. This state-of-the-art system has achieved first place in every MLPerf training benchmark, underscoring its status as the premier option for demanding AI tasks. Reports suggest that NVIDIA is the sole participant to have submitted results for every test, further widening the performance gap with its competitors. The platform has amassed “hundreds” of MLPerf Training and Inference wins in 2025 alone, showcasing remarkable results such as:
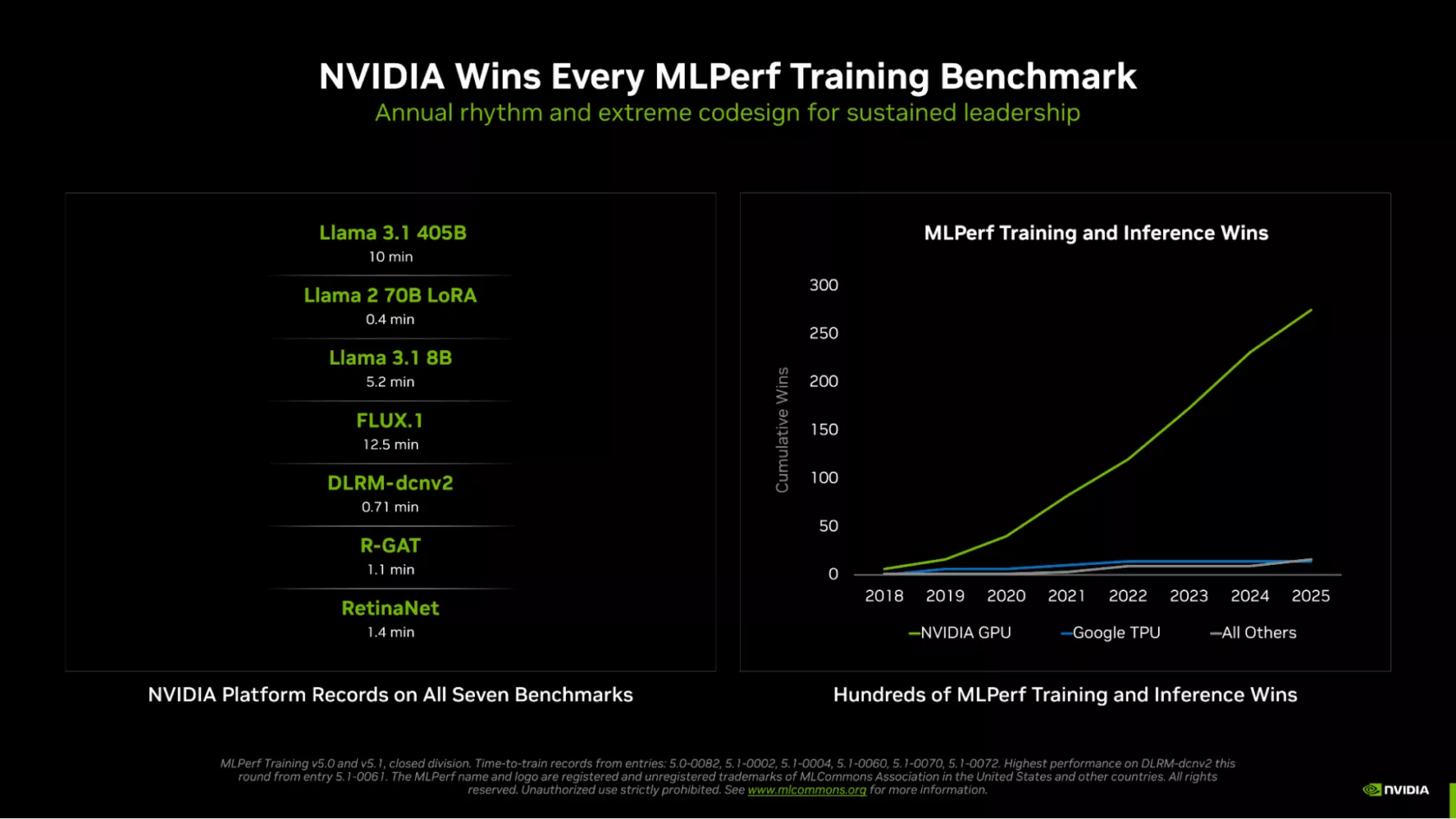
- Llama 3.1 405B: 10 min
- Llama 2 70B LoRA: 0.4 min
- Llama 3.1 8B: 5.2 min
- FLUX.1: 12.5 min
- DLRM-dcnv2: 0.71 min
- R-GAT: 1.1 min
- RetinaNet: 1.4 min
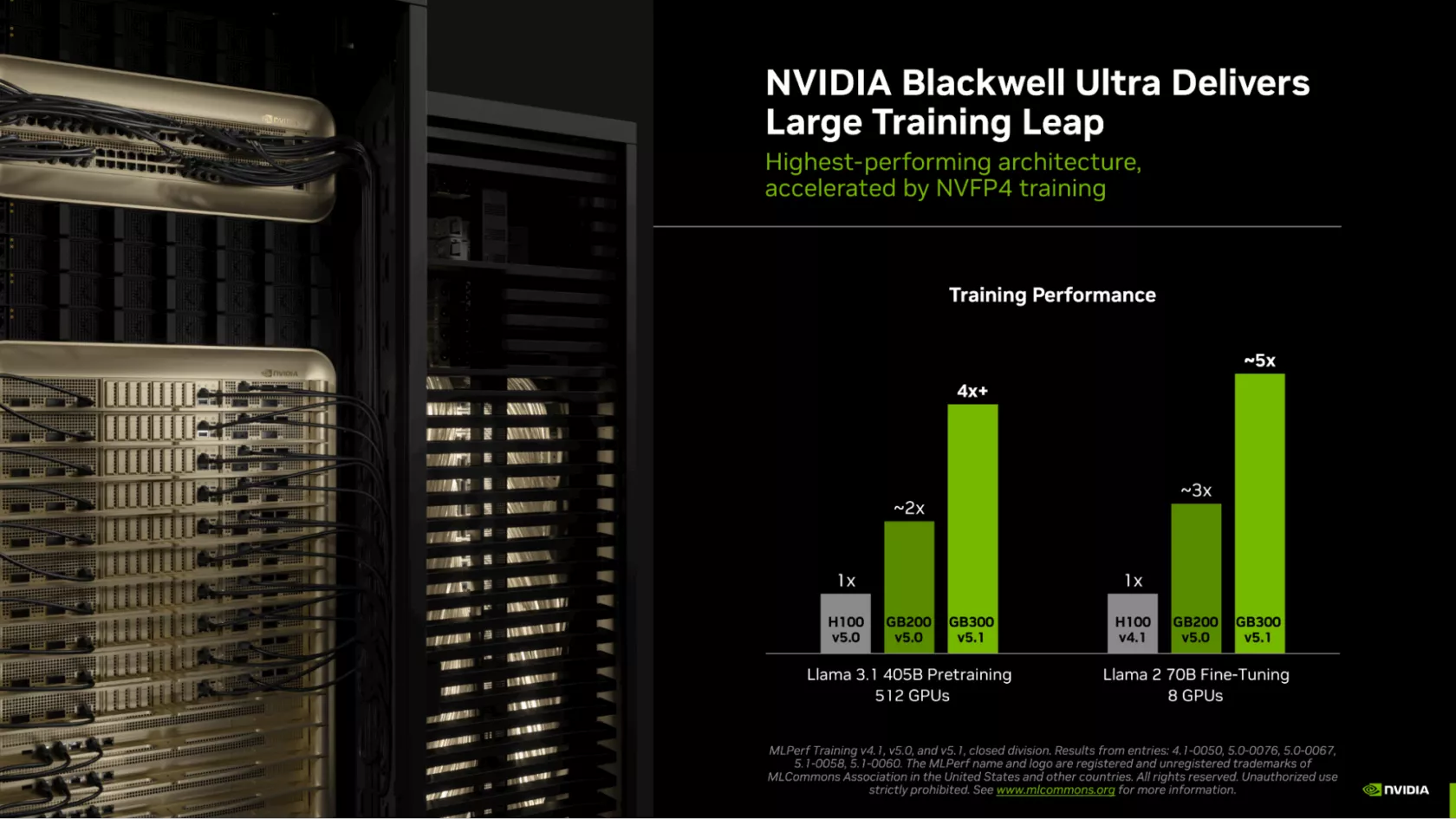
The GB300 NVL72 platform, utilizing the same number of Blackwell Ultra GPUs, has demonstrated over 4X the performance compared to the H100 and nearly 2X versus the Blackwell GB200 during Llama 3.1 40B pretraining. Additionally, in the Llama 2 70B Fine-Tuning, 8 GB300 GPUs delivered an astonishing 5X higher performance compared to the H100.
Revolutionary Memory and Precision Advancements
NVIDIA’s edge is further enhanced by its unparalleled CUDA ecosystem. The CUDA software stack is a key factor, but the rack system’s architecture and the Quantum-X800 InfiniBand at 800 GB/s networking speed are also unrivaled. The GB300 NVL72 is equipped with 279 GB HBM3e memory per GPU and a combined GPU and CPU memory total of 40 TB. This immense memory configuration is pivotal in accelerating AI workloads, with FP4 precision employed for superior training efficiency.
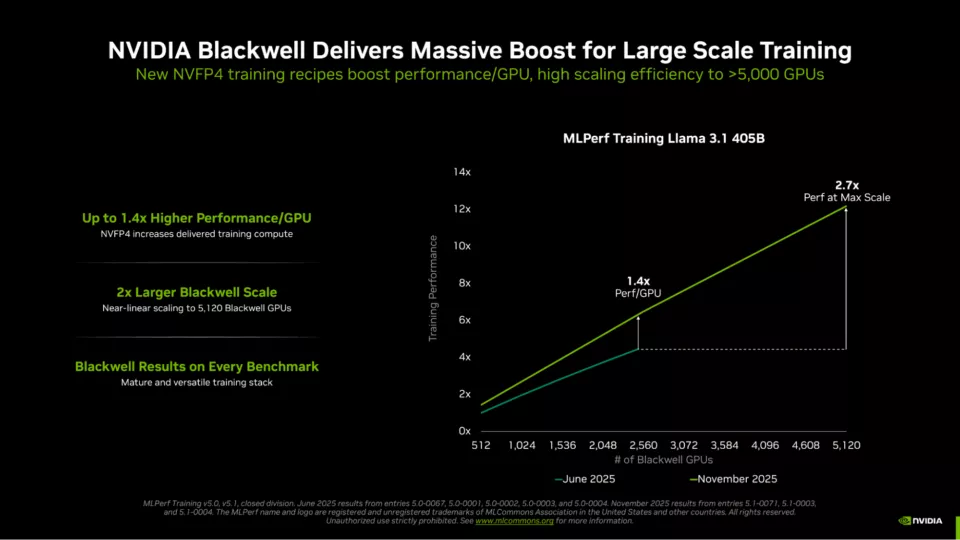
Employing FP4 precision in LLM training accelerates calculations, doubling the speed compared to FP8. The Blackwell Ultra elevates this advantage to 3X, enabling NVIDIA to deliver extraordinary performance without increasing the GPU count. The new results, achieved with 5,120 Blackwell GPUs, took merely 10 minutes to train the Llama 3.1 405B parameter, showcasing a significant improvement over the June submission.